A Generative Multi-Resolution Pyramid and Normal-Conditioning 3D Cloth Draping
Abstract
RGB cloth generation has been deeply studied in the related literature, however, 3D garment generation remains an open problem. In this paper, we build a conditional variational autoencoder for 3D garment generation and draping. We propose a pyramid network to add garment details progressively in a canonical space, i.e. unposing and unshaping the garments w.r.t. the body. We study conditioning the network on surface normal UV maps, as an intermediate representation, which is an easier problem to optimize than 3D coordinates. Our results on two public datasets, CLOTH3D and CAPE, show that our model is robust, controllable in terms of detail generation by the use of multi-resolution pyramids, and achieves state-of-the-art results that can highly generalize to unseen garments, poses, and shapes even when training with small amounts of data.
Architecture
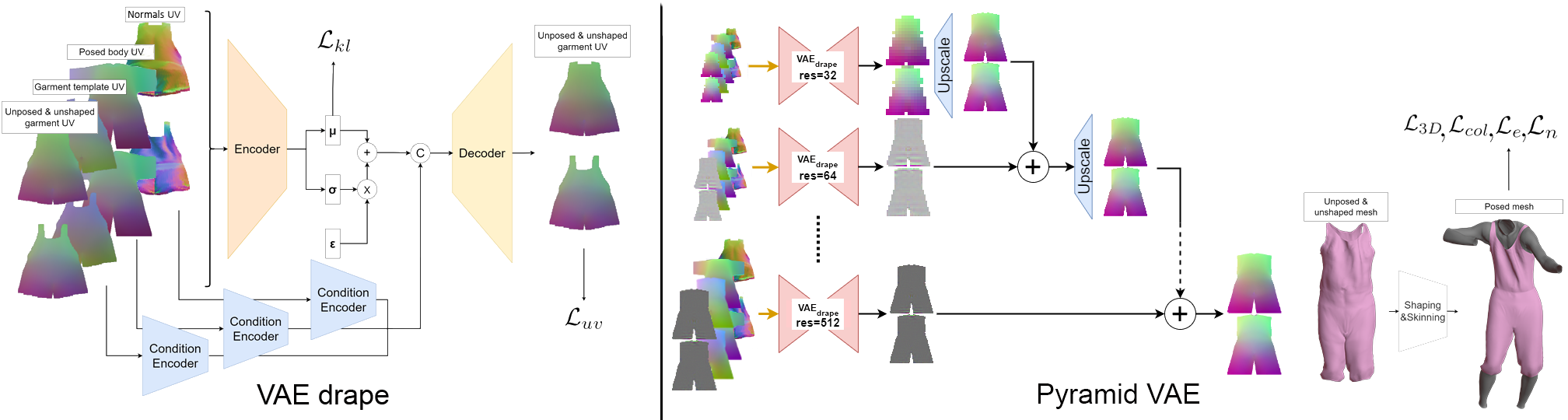
The proposed pyramid pipeline (right) contains basic VAE modules for each draping level (VAE_drape, left). VAE_drape receives conditioning inputs and garment offsets and reconstructs the unposed and unshaped garment offsets as UV image. In the case of the first level instead of offsets, absolute coordinates are used (as shown on the left) as this will serve as a base for subsequent levels. The conditioning variables (normals, posed body, and garment template UV images) are given into three pre-trained and frozen encoders to fuse with the VAE_drape latent code. These conditioning encoders are trained separately in an autoencoder manner. Finally, the reconstructed UV image is converted to a mesh and passed to the skinning module after reshaping. Then, in the pyramid module, the lowest resolution level predicts low-frequency garments while the other levels are learned as offsets over their previous level. Each level output is upscaled with the proposed upscaling network and summed to the next level.
BibTeX
@InProceedings{Laczko_2024_WACV,
author = {Laczko, Hunor and Madadi, Meysam and Escalera, Sergio and Gonzalez, Jordi},
title = {A Generative Multi-Resolution Pyramid and Normal-Conditioning 3D Cloth Draping},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {8709-8718}
}